ずっとPythonをやろうと思いながらやらないまま来てしまったので、「Python3エンジニア認定基礎試験」を受けることで無理やりやってしまおうという発想に至りました。まずは主教材である「Pythonチュートリアル」と、問題集「徹底攻略Python 3 エンジニア認定[基礎試験]問題集」を購入しました。
試験難易度としてはかなり低く、この資格があるからどうなるということはないのですが、ぼんやりと勉強するよりも効果的・効率的だと思うので、この試験の合格を通じて基礎の基礎をマスターしたいと思います。これまでオライリー本を読み切れたことがないので、よい機会だと思います。
以下に理解のメモを残しておきます。
オライリー: 1-2章

コマンドプロンプトでpyhtonと入力するとダウンロードが始まり、もう一度入力するとインタープリタが立ち上がります。
Ctrl + Zもしくはquit()でインタープリタを終了することができます。

Windowsのコマンドプロンプトのディレクトリの区切りはバックスラッシュ(\)である必要があります。なお、日本語フォントだとバックスラッシュはYenマークとして表示されてしまいます。
対話モードは、python と入力して >>> が表示された状態で、1行ずつPythonの命令を入力するとすぐに結果が返るモードです。スクリプト実行モードは、.py ファイルに書いたプログラムを python ファイル名.py のように実行して、ファイル全体をまとめて処理するモードです。
-c や -m は、Pythonを起動するときに使う「コマンドラインオプション(オプション引数)」です。Pythonに「いつもと違う実行の仕方をしてね」と指示するためのスイッチみたいなものです。
| オプション | 意味 | 例 |
|---|---|---|
-c | command の略。「1行だけのPythonコードを直接実行する」 | python -c "print('Hello')" |
-m | module の略。「指定したモジュールをスクリプトのように実行する」 | python -m http.server(→ 簡易Webサーバ起動) |
-V または --version | Pythonのバージョンを表示 | python -V |
-i | スクリプト実行後に対話モードを続ける | python -i script.py |
-c などを使うのは、 スクリプト実行モード(ファイルを使わない一時スクリプト)です。
| モード | 入力例 | 結果 | 主な用途 |
|---|---|---|---|
| 対話モード | python → >>> print("Hi") | Hi | 手動で試す |
| スクリプト実行 | python hello.py | Hello, Python! | 保存して実行 |
-c オプション | python -c "print('Hello, Python!')" | Hello, Python! | コマンド1行で実行 |
オライリー: 3章
- 除算
/は常に float(小数)を返す5 / 2 # → 2.5 4 / 2 # → 2.0→ 結果が割り切れても必ず小数になります。 - 整数のまま割り算したいときは
//(整数除算)を使う5 // 2 # → 2 -5 // 2 # → -3 (小数点以下切り捨て) - 余りを求めるには
%(剰余)を使う5 % 2 # → 1 -5 % 2 # → 1 (Pythonでは割る数の符号に合わせた結果になる) - 累乗は
**を使う2 ** 3 # → 8 - 整数と小数を混ぜると結果は float になる
3 + 2.0 # → 5.0 7 // 2.0 # → 3.0 divmod(a, b)で商と余りを同時に得られるdivmod(7, 3) # → (2, 1)
文字列リテラル(string literal)
プログラムの中で、直接クオートで囲んで書かれた文字列のことを言います。つまり、 ' ' や " "、''' '''、""" """ で囲まれた部分そのものが「文字列リテラル」です。
message = "Hello, world!" # ← これは文字列リテラル「リテラル」とは、“値をそのまま書く”という意味です。数値リテラルなら 10、文字列リテラルなら "Hello" のように、変数ではなく直接書かれた値のことです。
Pythonでは、隣り合った文字列リテラルは自動的に連結されるという特徴があります。
これは「+」を使わなくても文字列をつなげられる便利な仕組みです。
text = "Hello, " "world!"
print(text) # → Hello, world!上のように "Hello, " と "world!" の間に演算子がなくても、Pythonはコンパイル時に自動でくっつけて "Hello, world!" という1つの文字列にします。コードを読みやすくするために、長い文字列を複数行に分けたいときによく使われます。
message = (
"Pythonは、"
"シンプルで読みやすく、"
"強力なプログラミング言語です。"
)→ 出力結果:
Pythonは、シンプルで読みやすく、強力なプログラミング言語です。| 種類 | 書き方 | 結果 | 補足 |
|---|---|---|---|
| リテラル結合 | "Hello, " "Python!" | "Hello, Python!" | リテラル同士なら + 不要。実行前に自動結合される。 |
| 変数との結合 | "Hello, " + name | "Hello, Python" | 変数を含むときは + が必要。 |
| 数値との結合 | "Age: " + str(age) | "Age: 14" | 数値は str() で文字列に変換して結合する。 |
文字列の要素アクセスと部分抽出
Pythonでは、文字列の位置(インデックス)は0から始まります。最初の文字がインデックス0、2文字目がインデックス1というように、順に1ずつ増えていきます。そのため、word[0] は先頭の文字を指し、word[1:4] はインデックス1から3まで(2〜4文字目の直前まで) の範囲を取り出します。
つまり、Pythonでの「1〜3番目を取得」という表現は、「0から数えるインデックス体系に基づいた人間向けの説明」であり、実際には「インデックス1・2・3の要素を取得する」という意味になります。
(例:word = "Python")
🟩 インデックス指定(インデックスは0から始まる)
| 書き方 | 説明(インデックス基準) | 結果 |
|---|---|---|
word[0] | インデックス0(先頭の文字)を取得 | "P" |
word[1] | インデックス1(2文字目)を取得 | "y" |
word[-1] | インデックス-1(末尾の文字)を取得 | "n" |
word[-2] | インデックス-2(後ろから2文字目)を取得 | "o" |
🟦 スライス(開始を含み、終了の直前まで)
| 書き方 | 説明(インデックス基準) | 結果 |
|---|---|---|
word[1:4] | インデックス1〜3(2〜4文字目の直前まで)を取得 | "yth" |
word[:3] | インデックス0〜2(先頭から3文字)を取得 | "Pyt" |
word[2:] | インデックス2以降(3文字目から最後まで)を取得 | "thon" |
word[-3:] | インデックス-3以降(末尾3文字)を取得 | "hon" |
word[::2] | 2文字おきに取得(インデックス0,2,4,…) | "Pto" |
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
0 1 2 3 4 5 6 ← 境界のインデックス(スライス用)
-6 -5 -4 -3 -2 -1 0 ← 負の境界インデックス(スライス用)イミュータブル(不変体)
Pythonの文字列(str型)はイミュータブル(immutable)なオブジェクトです。イミュータブルとは、「一度作られた値の中身を変更できない」という性質を指します。そのため、文字列の特定の文字を直接書き換えることはできません。
たとえば、word = "Python" としたあとに word[0] = "J" のように先頭の文字を変更しようとすると、TypeError: 'str' object does not support item assignment というエラーが発生します。
これは、文字列オブジェクト自体が固定されたものであり、その内容を部分的に更新することが許されていないためです。文字列を変更したい場合は、既存の文字列をもとにして新しい文字列を作り直す必要があります。
たとえば、次のように書きます。
word = "Python"
new_word = "J" + word[1:]このコードでは "J" と "ython" を連結し、新たに "Jython" という文字列を生成しています。元の "Python" はそのまま残り、変更されることはありません。
このように、Pythonの文字列は作成後に内容を変えず、常に「新しいオブジェクトを作って置き換える」という仕組みで動作しています。この特性により、文字列の操作が安全で予測可能になっているのです。
raw文字列(生文字列)
raw文字列(そのまま=生のまま)は、バックスラッシュ(\)を特別扱いしない文字列のことです。通常の文字列では、\n が改行、\t がタブなどの「エスケープシーケンス」として処理されますが、raw文字列ではそれらをそのままの文字として扱います。
# 通常の文字列
print("C:\new_folder") # → C:
# ew_folder (\nが改行になる)
# raw文字列
print(r"C:\new_folder") # → C:\new_folder (そのまま出力)先頭に r または R を付けることでraw文字列を表します。
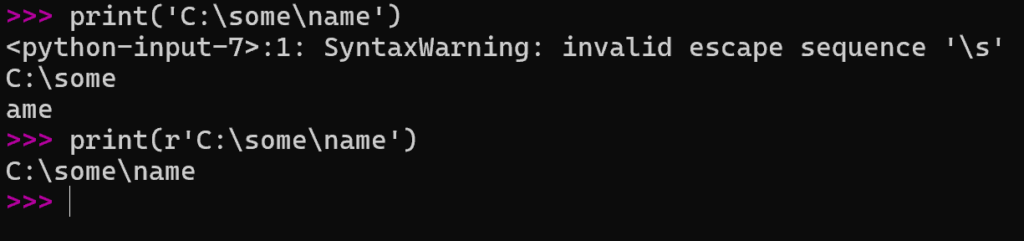
前者の\s は、定義されていないエスケープシーケンス」として SyntaxWarning が出ます。後者のように r を付けた raw文字列リテラル では、バックスラッシュを特別扱いせず、文字そのままに出力します。
f文字列
通常、文字列を作るときは "..." や '...' で囲みますが、その前に f を付けると、文字列の中に変数や式を直接埋め込める 特別な構文になります。
name = "Alice"
print(f"こんにちは、{name}さん!")出力:
こんにちは、Aliceさん!ここで {name} の部分が、変数 name の中身に置き換えられています。つまり、f"..." の中では {} の中にPythonの式が書けるんです。
x = 5
y = 3
print(f"{x} + {y} = {x + y}")出力:
5 + 3 = 8中括弧 {} の中では計算式もOK。普通に変数の値を埋め込むよりずっと便利です。
リスト
Pythonのリストは、複数の値を順番にまとめて扱うためのデータ構造です。1つの変数の中に、いくつものデータを「順序つきの集合」として保存できます。たとえば、次のように書くことができます。
fruits = ["apple", "banana", "cherry"]この fruits という変数には、3つの文字列 "apple", "banana", "cherry" が順番に並んだリストが入っています。リストは角かっこ(かくかっこ) [ ] で囲んで表し、要素はカンマ , で区切ります。
Pythonのリストには、次のような性質があります。
- 順序をもつ(ordered)
要素には順番があり、インデックス(番号)でアクセスできます。
先頭の要素はインデックス0、次が1、というように数えます。 - ミュータブル(mutable)
作ったあとでも、中身の要素を変更・追加・削除できます。
これは、文字列(イミュータブル)との大きな違いです。 - 異なる型を混在できる
同じリストの中に、文字列・数値・他のリストなど、
異なる種類のデータを入れることができます。
関数とメソッド
Pythonでは、あらゆるデータは「オブジェクト」として扱われ、その性質と動作はクラス(class)によって定義されています。クラスは、オブジェクトがどのようなデータ(属性)を持ち、どのような操作(メソッド)を行えるのかを決める「設計図」のようなものです。
このクラスという仕組みをもとに、Pythonではあらかじめ多くの型(type)が定義されています。たとえば、int は整数を表すクラス、str は文字列を表すクラス、list はリストを表すクラスです。それぞれの型は、内部的にはクラスとして実装されており、これらがPythonの基本的なデータ型を構成しています。したがって、Pythonにおける「型」は、クラスの一種と言えます。
クラスから実際に生成されたオブジェクトをインスタンスと呼びます。たとえば、"Python" という文字列は str クラスのインスタンスであり、[1, 2, 3] というリストは list クラスのインスタンスです。インスタンスはそれぞれのクラス(型)に基づいて作られているため、同じように見えるオブジェクトでも、型が異なれば動作の仕方も異なります。
各クラスの中には、その型が行える操作を定義したメソッド(method)が存在します。メソッドとは、特定の型に紐づけられた関数のようなもので、たとえば文字列型(str)には .upper() や .replace() のように文字列を操作するメソッドが、リスト型(list)には .append() や .pop() のように要素を操作するメソッドが定義されています。このように、メソッドは「その型に固有の動作」を定義するものであり、同じ名前のメソッドでも、属する型が違えば意味も動作も異なります。
一方で、関数(function)は、特定のクラスに属さない独立した処理の単位です。たとえば len() や print()、sum() といった関数は、クラスの中ではなく、Python全体に組み込まれた「ビルトイン関数」として定義されています。関数はオブジェクトを引数として受け取り、その結果を外から返すという形で動作します。これに対して、メソッドは「オブジェクト自身」に対して呼び出され、その内部状態を参照したり、変更したりするという点で性質が異なります。
つまり、Pythonの世界では、クラスが型を定義し、その型がメソッドを持ち、メソッドは型に固有の操作を実現します。そして、関数はそれらとは独立して、型に依存しない一般的な処理を提供します。
すべてのオブジェクトはクラスから生まれ、クラスが「型」という概念を形作り、型が持つメソッドがそのふるまいを定義し、関数がそれらを外から操作する。このように、Pythonの仕組みはクラスを中心に構成されており、クラス・型・メソッド・関数はそれぞれが役割を分担しながら、一体となって動作しているのです。
| 名称 | 種類 | 主な使い方 | 対象 | 意味 |
|---|---|---|---|---|
len() | ビルトイン関数(built-in function) | len(list) | すべてのシーケンス型(リスト、文字列、タプルなど) | 要素の個数(長さ)を求める |
append() | メソッド(method) | list.append(x) | リスト型(list)のみ | リストの末尾に要素を追加する |
len() はビルトイン関数
len() は Python にもともと組み込まれている「関数」です。リストだけでなく、文字列やタプルなど、「長さ(要素数)」をもつあらゆるオブジェクトに使えます。
fruits = ["apple", "banana", "cherry"]
print(len(fruits)) # 3
print(len("Python")) # 6ここで len() は、外からオブジェクトを引数として受け取り、その長さを返す関数です。
append() はメソッド
一方で append() は、リスト専用のメソッド(=オブジェクトに属する関数)です。使うときは、リストオブジェクトのあとに「ドット(.)」をつけて呼び出します。
fruits = ["apple", "banana"]
fruits.append("cherry")
print(fruits) # ['apple', 'banana', 'cherry']このとき append() は、リストそのものを変更(更新)します。つまり、append() はリストの「ふるまい(操作)」に紐づいた関数=メソッドです。
関数とメソッドの関係イメージ
関数(function) → 外からオブジェクトを操作する
メソッド(method)→ オブジェクト自身がもつ操作len(fruits)は「関数がリストを調べて長さを返す」fruits.append("x")は「リスト自身が自分に要素を追加する」
オライリー: 4章
forループとイテラブル
素数(1と自分自身以外に割り切れる整数をもたない、2以上の自然数)探索ループを考えます。このコードは「1と自分自身以外で割れる数があるかどうかをすべて試して判定している」という内容になっています。なお、英語では素数を「prime number」と呼びます。
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, 'equals', x, '*', n // x)
break
else:
print(n, 'is a prime number')出力は以下のとおりです。
2 is a prime number
3 is a prime number
4 equals 2 * 2
5 is a prime number
6 equals 2 * 3
7 is a prime number
8 equals 2 * 4
9 equals 3 * 3終端は含まないので、xが2の時にはelseとなります。外側ループが1増えるたびに、内側ループは (n − 2) 回 回ることとなります。
Python では、for ... in ...: の右側に置けるもの(range, list, tuple, str, など)はすべてイテラブルです。
| 型 | イテラブル? | 例 |
|---|---|---|
| list | ✅ | [1, 2, 3] |
| tuple | ✅ | (1, 2, 3) |
| str | ✅ | 'abc' |
| dict | ✅ | {"a": 1, "b": 2} |
| set | ✅ | {1, 2, 3} |
| range | ✅ | range(2, 10) |
| int / float | ❌ | 10, 3.14(←イテラブルではない) |
関数の定義
フィボナッチ級数を表示する関数を定義します。
フィボナッチ級数(フィボナッチ数列)とは、最初の2つの項を0と1とし、その後の各項を直前の2つの項の和として定義する数列のことです。式で表すと、( F_0 = 0, F_1 = 1 )、そして ( F_n = F_{n-1} + F_{n-2} )(n ≧ 2)となります。この規則に従うと、数列は「0, 1, 1, 2, 3, 5, 8, 13, 21, 34,…」のように続いていきます。
この数列は一見単純に見えますが、自然界のさまざまな現象に深く関係していることで知られています。たとえば、ひまわりの種の並び方、貝殻の渦の形、松ぼっくりのうろこの配置などに、フィボナッチ数列の規則性が見られます。また、隣り合う項の比は「黄金比」(約1.618)に近づくため、美術や建築、デザインの分野でも重要な役割を果たしています。
プログラミングの分野では、フィボナッチ級数は「前の2つの値を足して次を求める」というシンプルな再帰的構造を持つため、ループ処理や再帰関数の練習題材としてよく用いられます。フィボナッチ級数は、数学的にもコンピュータ科学的にも「成長」や「秩序」を象徴する、美しく興味深い数列です。
def fib(n):
"""nまでのフィボナッチ数列を表示する"""
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a + b
print()「def」は関数を定義するキーワード
def 関数名(引数):
処理という形で、何度でも呼び出せる処理のまとまり(=関数)を作ります。
fib(n) の例は「フィボナッチ数列を表示する関数」
def fib(n):
"""nまでのフィボナッチ数列を表示する"""
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a + b
print()
➡ この関数は、fib(1000) と書くと「1000未満のフィボナッチ数列」を出力します。
""" ... """ は「ドキュメンテーション文字列(docstring)」
関数の最初に書く三重引用符の文字列は説明書きです。Pythonではこれを自動的に関数の説明として扱います。
たとえば:
help(fib)
とすると、このdocstringがヘルプに表示されます。
return がない関数の戻り値について
この fib 関数は、「値を返す(return)」のではなく、画面に結果を表示するだけの関数です。Pythonではこのような関数を「手続き(procedure)」と呼びます。
関数を実行しても結果を受け取れないため、
x = fib(10)としても、x の中身は None(=何も返さないことを示す特別な値) になります。
つまり、「return がない関数は意味のある値を返さない」ものの、Python内部では自動的に None が返されている ということです。
一方で、次のように return を使えば、値を返す関数にすることができます。
def fib2(n):
"""nまでのフィボナッチ数列をリストで返す"""
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a + b
return resultfib2(10)
# → [0, 1, 1, 2, 3, 5, 8]のようにリスト(配列)として値を返すことができます。
問題集: 第1章
Pythonは、事前にコンパイルを行う必要がなく、実行時にソースコードをバイトコードという中間形式に変換し、そのバイトコードをPython仮想マシン(PVM)が逐次解釈して実行するインタープリタ型言語です。
Pythonでは、if文などの制御構造あるいは関数のような処理のまとまり(ブロック構造)を表すとき、括弧ではなくインデントを用います。このとき、タブではなくスペースを使うことが推奨されています。理由は、環境によってタブの幅が異なるため、見た目は同じでもPythonが正しく判断できずエラーの原因になることがあるからです。そのため、公式スタイルガイド(PEP 8)でも「インデントにはスペース4つを使う」ことが推奨されています。
Pythonでは、処理を高速化したり新しい機能を追加したりするために、C言語などで書かれたプログラムを組み込むことができます。たとえば、NumPyやpandasといったライブラリは内部でC言語のコードを利用しており、Pythonから高速に数値計算やデータ処理を行えるようになっています。
Pythonを対話モードで起動すると、次のような表示が出ます(例):
Python 3.12.1 (tags/v3.12.1:123456, Dec 5 2024, 12:34:56) [MSC v.1937 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>この >>> が一次プロンプトで、ここからPythonの命令を1行ずつ入力して実行できます。
Pythonの対話モードでは、1行ずつ入力してすぐに結果を確認できます。通常の入力行の先頭には 「>>>」(一次プロンプト) が表示され、if文や関数定義など、ブロックを続けて書く場合には 「...」(二次プロンプト) が表示されます。
たとえば:
>>> if True:
... print("Hello")
...
Helloこのように、>>> が新しい入力の始まり、... がブロックの続きであることを示します。
Pythonでは、プログラム中の文字を数値として保存・読み込むために「エンコード(文字コード)」という仕組みを使います。現在のPythonでは、その標準方式としてUTF-8が採用されています。UTF-8は世界中の文字を共通のルールで表現できるため、英語や日本語などを混ぜても文字化けが起こりにくく、特別な設定をしなくても日本語を正しく扱えるという特徴があります。
以下はPythonで文字列を表す際に使われる3種類のクオート(シングル・ダブル・トリプル)の違いと用途をまとめたものです。
| 種類 | 記号 | 用途 | 備考 |
|---|---|---|---|
| シングルクオート | ' ' | 短い文字列 | 'Hello' |
| ダブルクオート | " " | シングルクオートを含む文字列 | "I'm fine" |
| トリプルクオート | ''' ''' / """ """ | 複数行の文字列やdocstring | 複数行の文章をそのまま書ける |
| 種類 | 書き方 | 内容 |
|---|---|---|
| 1行コメント | # これはコメント | #以降は実行されない |
| 複数行コメント(擬似的) | """ ... """ | 実際は文字列だが、変数に代入しなければ実行時に無視されるため、コメントのように使われる |
問題集: 第2章
1.
x = 100 - 5**2 + 5 / 5
print(x)x の途中で 5 / 5 により浮動小数点が混ざるため、計算全体の結果 x も float型(76.0) になります。
Pythonでは、除算 / の結果を常に小数にするのは、数学的に正しい割り算の結果をそのまま返す方が自然だからです。たとえば、学校で学ぶ算数では「5 ÷ 2 = 2.5」であり、「2」ではありません。ところが、従来の多くの言語(やPython 2)では、整数同士の除算では小数点以下が切り捨てられ、結果が 2 になっていました。これは「型(整数)」に合わせた機械的な動作であり、人間の感覚から見て不自然です。
そのためPython 3では、「割り算なら必ず数学的な答えを返す」という方針に変わりました。整数か小数かに関係なく、/ は常に実際の割り算を行い、結果を浮動小数点として返します。これにより、コードを読む人が「整数だから結果が切り捨てられるかも」と考える必要がなくなり、数学的直感と一致した、より一貫した言語仕様になっています。
7.
price = 15000
print(f"価格:{price:7d}")この問題の趣旨は、Pythonのフォーマット指定子における幅指定({price:7d})の意味を理解しているかを確認することにあります。{price:7d} のうち、price は出力する変数を示し、d は整数(decimal)として表示するという意味を持っています。その間にある 7 は、出力全体の幅を7文字分確保するという指定です。Pythonのフォーマットでは、幅を指定した場合、デフォルトで右寄せになります。したがって、出力される数字が7桁に満たない場合、左側に空白が挿入されて右端がそろうように表示されます。このコードの場合、price の値は15000であり、数字は5桁です。7桁分の幅を指定しているため、2文字分の空白が左側に追加され、結果として " 15000" という文字列が生成されます。これを print() 関数で出力すると、実際の表示は次のようになります。
価格: 15000この空白は右寄せのために挿入されたものであり、数値の前(左側)に入ることがポイントです。もしゼロで埋めたい場合は :07d のように「0」を追加して指定し、0015000 のような形にすることもできます。また、左寄せにしたい場合は :<7d、中央寄せにしたい場合は :^7d と記述します。したがって、この問題で正しい出力は「価格:␣␣15000」(␣は空白)であり、空白が頭(左側)に入ることを理解しているかが問われています。
8.
import math
print(f"πの値はおよそ{①}である")コードではまず import math によって数学用のモジュールを読み込み、その中に含まれる円周率の定数math.pi を使っています。math.pi は約 3.141592653589793 という浮動小数点数を返します。次に、print(f"πの値はおよそ{①}である") の部分では、f文字列(フォーマット済み文字列リテラル)を用いて、文字列の中に変数や値を埋め込んで表示しています。f文字列では、波かっこ {} の中に変数を書くだけでなく、コロン : に続けて表示形式を指定することができます。
たとえば、{x:.5f} のように書くと、「小数点以下5桁まで表示し、余分な部分は四捨五入する」という意味になります。この .5f のうち、5 は小数点以下の桁数、f は「固定小数点表記(floatの通常表示)」を表しています。したがって、math.pi を小数点以下5桁で表示したい場合は、{math.pi:.5f}と書くのが正しい形式です。このように書くことで、math.pi の値(3.1415926535…)が丸められ、出力結果は次のようになります。
πの値はおよそ3.14159である10.
.format() は以下の2通りの指定ができます:
- 位置引数 →
.format(x, y, z){0},{1},{2}で参照{}でも自動的に順番で埋められる
- キーワード引数 →
.format(x=300, y=150, z=200){x},{y},{z}で参照
A.
x = 300
y = 150
z = 200
print("spam: {0}, ham: {1}, eggs: {2}".format(x, y, z))
.format()に3つの位置引数(x, y, z)を渡している。- 文字列内の
{0},{1},{2}は、それぞれ順に 1番目・2番目・3番目の引数を参照する。 - したがって:
{0}→x = 300{1}→y = 150{2}→z = 200
位置と対応して正しく値が埋め込まれる。
B.
x = 300
y = 150
z = 200
print("spam: {x}, ham: {y}, eggs: {z}".format(x, y, z))
.format() に渡しているのは位置引数なのに、中では {x} {y} {z} という 名前指定をしている。そのため、Pythonは「x という名前の引数がない」と判断し、KeyError: 'x' を出す。
C.
x = 300
y = 150
z = 200
print("spam: {}, ham: {}, eggs: {}".format(x, y, z))
{}の中を空にすると、Python 3.1以降では自動的に0番から順に対応するようになっている。.format(x, y, z)とした場合:- 1番目
{}→x = 300 - 2番目
{}→y = 150 - 3番目
{}→z = 200
- 1番目
つまり、Aとまったく同じ結果になるが、番号を省略して書ける「簡略記法」。
D.
x = 300
y = 150
z = 200
print("spam: {a}, ham: {b}, eggs: {c}".format(a=x, b=y, c=z)).format()に キーワード引数 を使って値を渡している。{a},{b},{c}は、format()に渡された引数名と対応する。- つまり:
{a}→a=x=300{b}→b=y=150{c}→c=z=200
名前で対応しているので、順番に依存せず柔軟に使える。
問題集: 第3章
5.
Pythonでは、リストの中に別のリストを要素として含めることができる。このように、あるデータ構造の中に同じ種類の構造を入れることを「入れ子(ネスト)」という。たとえば [[1, 2], [3, 4]] は、外側のリストの中に2つのリスト [1, 2] と [3, 4] が入っている構造であり、「リストの入れ子」と呼ばれる。
リストの長さ(len())は、外側のリストが直接持つ要素の数を指す。したがって、[[1, 2], [3, 4]] の場合、外側のリストの中に要素が2つ(内側リストが2つ)あるので、長さは2となる。
一方で、[[1, 2, 3, 4]] のように、外側のリストが内側リストをひとつだけ持つ場合、その長さは1になる。[1, 2, 3, 4] という内側リストの中に4つの値が入っていても、外側から見ればそれは「要素1つ分」として数えられるためである。このため、「[[1, 2, 3, 4]] の長さは4である」という記述は誤りとなる。
また、Pythonでは [ [1, 2], [3, 4, 5] ] のように、内側リストの長さが異なっていても同じ外側リストに含めることができる。リストは要素の型や構造を統一する必要がない柔軟なデータ構造であるため、このような異なる長さの入れ子も問題なく扱える。
以上より、設問における誤った記述は「[[1, 2, 3, 4]] の長さは4である」としたBである。このリストの長さは正しくは1であり、リストの入れ子構造と長さの概念を混同している点が誤りである。
6.
リストの構造は次の通り:
data = [
[1, 2], ← data[0]
[3, 4] ← data[1]
]インデックスで指定すると:
data[0][0]→ 1data[1][1]→ 4
よって出力は:
print(data[0][0], data[1][1])
# 出力: 1 47.
コード:
stack = [1, 2, 3, 4]
data = []
while stack:
data.append(stack.pop())
print(data)実行の流れ:
stack.pop() は 末尾の要素を取り出す。ループは stack が空になるまで続く。
| ループ回数 | stackの状態 | 取り出される値 | dataの状態 |
|---|---|---|---|
| 1 | [1, 2, 3] | 4 | [4] |
| 2 | [1, 2] | 3 | [4, 3] |
| 3 | [1] | 2 | [4, 3, 2] |
| 4 | [] | 1 | [4, 3, 2, 1] |
出力結果は:
[4, 3, 2, 1]8.
コード:
data = [0]
data.append(1)
data.pop(0)
print(data)実行の流れ:
data = [0]data.append(1)→[0, 1]data.pop(0)→ index 0 の要素 0 を削除 →[1]
出力結果:
[1]data.pop(0) が「0番目を削除する」理由は、pop() が「指定したインデックスの要素を取り出して削除する」メソッドだからです。 なお、pop() の「結果(戻り値)」は “取り出した(削除された)要素” です。
残った方ではありません。一方、この問題は pop() の戻り値(取り出した値) はどこにも使われていません。
つまり、「取り出したもの」には興味がなく、削除後に残ったリストの方を見ている という構造です。
list.pop([i])i(インデックス)を指定すると、その位置の要素を削除して取り出した値を返す。- 引数を省略すると、末尾(-1番目) の要素を削除して返す。
data = [10, 20, 30]| コード | 動作 | 結果のリスト | 戻り値 |
|---|---|---|---|
data.pop() | 最後を削除 | [10, 20] | 30 |
data.pop(0) | 先頭(インデックス0)を削除 | [20, 30] | 10 |
data.pop(1) | 2番目(インデックス1)を削除 | [10, 30] | 20 |
9.
コード:
data = []
for i in [1, 2, 3]:
for j in [1, 2, 3]:
if i != j:
data.append([i, j])
print(data)流れ:
i と j が同じでないときだけ [i, j] を追加。したがって、(i, j) の組み合わせは:
(1,2), (1,3),(2,1), (2,3),(3,1), (3,2)結果:
[[1,2], [1,3], [2,1], [2,3], [3,1], [3,2]]一致するのはAとなる。
print([(i, j) for i in [1, 2, 3] for j in [1, 2] if i != j])補足メモ
言語比較
| 観点 | 🟢 C言語 | 🟣 Solidity | 🟠 Python |
|---|---|---|---|
| 🧱 言語の分類 | コンパイル型(ネイティブ) | コンパイル型(仮想マシン用) | インタプリタ型(仮想マシン用) |
| ⚙️ コンパイルの必要性 | ✅ 必要(機械語へ変換) | ✅ 必要(EVMバイトコードへ変換) | ⚠️ 実行時に自動コンパイル(.py → .pyc) |
| 🧠 出力結果 | CPUが直接理解できる機械語(.exe / ELF) | EVM命令(バイトコード:0x6080…) | Pythonバイトコード(.pyc) |
| 💻 実行環境 | OS+CPU(物理的なマシン) | Ethereumノード上のEVM(仮想CPU) | Python仮想マシン(PVM) |
| 🧩 仮想マシン | ❌ 使わない(ネイティブ実行) | ✅ EVM(Ethereum Virtual Machine) | ✅ PVM(Python Virtual Machine) |
| 🔄 実行の流れ | ソース → コンパイル → 機械語 → CPU実行 | ソース → コンパイル → EVMバイトコード → EVM実行 | ソース → (即時) バイトコード → PVMで逐次実行 |
| 🧮 実行速度 | ⚡ 非常に速い(CPU直実行) | 🐢 遅い(EVM上で逐次実行) | 🐢 遅い(解釈実行) |
| 🌍 移植性 | 低い(CPU/OS依存) | 高い(どのEVMでも同じ動作) | 高い(どのOSでも同じ) |
| 🔐 安全性・サンドボックス性 | 低い(メモリ破壊も可能) | 高い(ガス制限・分散実行) | 中程度(VM内で隔離) |
| 🔍 主な用途 | OS・ドライバ・高速アプリ | スマートコントラクト | スクリプト・データ分析・AI |
| 🧾 出力の例 | a.out, program.exe | EVMバイトコード(on-chain) | .pyc(自動生成される中間ファイル) |
| 🧰 代表的なコンパイラ/実行環境 | GCC / Clang | solc / Hardhat / Foundry | CPython / PyPy |
🔹 C言語
Cはコンパイル型のネイティブ言語です。書いたプログラムはコンパイラ(GCCなど)によって、CPUが直接理解できる機械語に変換されます。つまり、仮想マシンのような仲介層は存在せず、プログラムはOSとCPUに直接命令を出します。
そのため、動作は非常に速く、システム開発やゲームエンジンなど性能が重要な場面で使われます。ただし、生成される実行ファイルはOSやCPUに依存するため、別の環境で動かすには再コンパイルが必要になります。言い換えると、「速いけれど融通が利かない」タイプです。
🔸 Solidity
Solidityはブロックチェーン(Ethereum)専用のコンパイル型言語です。書いたコードはコンパイルされて、EVM(Ethereum Virtual Machine)が理解できるEVMバイトコードになります。このEVMは世界中のEthereumノードに同じ仕様で組み込まれており、どのノードでも同じ結果になるように分散して実行されます。
つまり、Solidityは「ブロックチェーン上で動く共通の仮想マシン(EVM)」に向けて命令を書いているイメージです。セキュリティや透明性は高いですが、EVM上で逐次実行されるため、速度は遅くコスト(ガス代)もかかります。「遅いけど、全世界で同じように動く」安全重視の言語です。
🟠 Python
Pythonはインタプリタ型のスクリプト言語です。ソースコードをそのまま1行ずつ解釈しながら実行します。正確には、実行時に一度だけバイトコード(.pyc)に変換し、それをPVM(Python Virtual Machine)が読み取って実行します。
この仕組みにより、環境を選ばずに動作し、AI・データ分析・自動化など柔軟さや開発スピードを重視する用途に向いています。ただし、逐次解釈されるため、Cよりも圧倒的に遅いという欠点があります。「使いやすくてどこでも動くけど、速さは犠牲にしている」言語です。

コメント